In this document High Availability (HA) is the term used to describe the hardware, software and processes designed to eliminate single points of failure and provide redundancy to ensure your mission critical Patriot monitoring systems located at the primary site have the greatest possible uptime. Disaster Recovery (DR) on the other hand refers to redundant hardware and software situated in a remote location (offsite) so that in the event of a catastrophic disaster monitoring operations can be relocated with the least possible downtime and disruption. There is a direct trade-off between cost and the level of downtime that can be tolerated which must be carefully considered when deciding what HA and DR strategies to put in place. Hardware or operating system failure at the primary site (e.g. disk failure, power failure, network fault, memory error, processor fault or an operating system update that goes wrong) is significantly more likely to occur than a catastrophic disaster. For this reason High Availability measures introduced at the primary site are likely to yield the greatest return in uptime. However disasters such as floods, fires, earthquakes, long term power outages and major power surges do happen but as they are far less frequent a greater downtime is usually tolerable.
The risk of hardware failure can be mitigated considerably with quality hardware components with built in fault tolerance and redundancy. This includes backup power generation, UPS systems, redundant power supplies, redundant network connections, redundant fans, ECC error correcting memory, raided hard drives, hot swappable hard drives, Storage Area Networks (SANs) and Network Attached Storage (NAS). However these measures are beyond the scope of this document and should be considered alongside budget constraints and in consultation with IT professionals.
There are numerous possible HA and DR strategies; below is a brief outline of some suggested best practices recommended by Patriot but by no means intended to be exhaustive. To provide the highest level of redundancy and automatic failover, Patriot recommends running the SQL Server and the Patriot Services on a Microsoft Windows Failover Cluster. Alternate lower cost options that require less software and hardware are also available. See Database Mirroring, (note Microsoft have indicated their intention to deprecate SQL Database Mirroring in future versions of SQL Server). Log shipping is also still a useful solution for offsite DR.
In line with Microsoft recommendations our preferred HA & DR solution for later releases of SQL (2012, 2014 & 2016) Enterprise edition is AlwaysOn Availability Groups (AOAG) and AlwaysOn Failover Cluster Instance (FCI) built on a Windows Server Failover Cluster (WSFC). AlwaysOn Availability Groups have also recently been made available in SQL Standard Edition (2016) but with some limitations.
Planning and implementing High Availability and Disaster Recovery strategies can be quite an involved process that should only be undertaken by IT professionals working in consultation with the Patriot support team.
It is important to realize High availability and disaster recovery measures do not replace the need for regular (automated) backups. Whereas HA and DR strategies are intended to mitigate downtime resulting from hardware or software failures, regular backups are required to protect against data loss (e.g. unintended mass deletion) or unexpected data corruption.
SQL clustering is available in later versions of SQL (2012, 2014 & 2016) Enterprise using Always On Availability Groups (AOAG) and AlwaysOn Failover Cluster Instance (FCI) features.
Patriot supports connection to an SQL clustered database. SQL Clustering can make available built in hardware redundancy and provide automatic failover within the cluster. Failover from hardware failure can occur instantaneously with virtually no disruption to the Patriot services. Patriot has Service Orientated Architecture (SOA) so that clients communicate with the Patriot Data Service in a restful disconnected fashion. Should the Data Service failover to a different node within its cluster instance, the Patriot Windows Client will reconnect once the failover has completed and the failover should go virtually unnoticed by the end user (no shutdown and restart of the client is required)..
There are many possible configurations for SQL clustering. Ultimately it depends on how much redundancy you wish to have vs how much money you wish to invest. Three example configurations are detailed below.
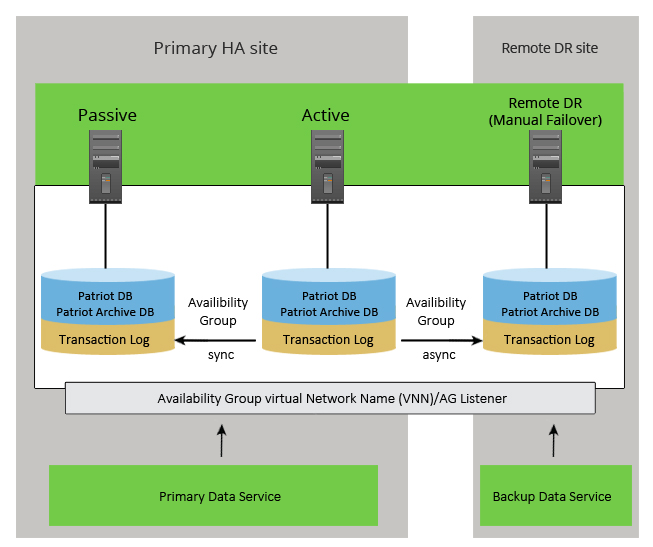
Always On Availability Groups (AOAG) provides protection on the database level rather on the instance level, allowing multiple databases to fail over as a single unit. The Patriot database and PatriotArchive database must be placed in the same AOAG. The AOAG does not require shared disk architecture like a Failover Cluster Instance (FCI) despite the fact it is built on a Windows Server Failover Cluster (WSFC). This means that each Availability Group replica has its own copy of the database, which removes the single point of failure inherent with shared storage but adds additional storage space requirements for each AG replica.
This solution requires SQL Enterprise edition and each replica has its own seperate storage location. Note that at the primary site the availability group is set to use synchronous mode. Synchronous replicas add slight latency to the database transactions because the primary needs to receive the acknowledgement that log records have been hardened to the secondary replica logs before the primary replica commits the transaction. In other words the primary replica waits for a synchronous-commit from the secondary replica to acknowledge before committing a transaction to ensure that the secondary replica database is always synchronized with the primary replica database. As the network path to the remote site is likely to be less reliable and have greater latency asynchronous mode should be used. With asynchronous-commit mode the primary replica commits transactions without waiting for acknowledgment from the secondary replica. Asynchronous-commit mode minimizes transaction latency but enables the secondary replica to lag behind the primary replica, increasing the possibility of a failure or possible data loss. Under normal conditions however the database in the remote DR site should only be a few seconds behind the primary database so very little if any data loss will occur should operations be switched to the Disaster Recovery (DR) site.
All replicas for an availability group must exist on a single Windows Server Failover Cluster (WSFC) within a single Active Directory domain, even between data centers. Manual failover to the DR site is required should both the primary and secondary replicas be taken down at the Primary site.
Two distinct copies of the Patriot Data Service and Task Service are required, one at the Primary site and one at the Remote DR site. Manual failover to the DR site is required. This is in line with best practice recommended by most industry experts. Providing the correct processes have been put in place as summarized below in the Disaster Recovery section, changeover to the DR site will involve little more than starting the Patriot Promote DR Utility which will automatically activate all failover procedures required.
The scenario below also requires SQL Enterprise solution and is similar to the one above except that it requires an additional node but has some high availability advantages in that the whole SQL server instance is failed over along with all databases in the instance (not just those in the availability group) - the first and second sql servers in the Failover Cluster Instance (FCI) use shared storage. Node2 would require manual failover similar to the DR but does provide onsite protection against loss of the shared storage hardware.
The DR site can be a standalone instance of SQL or be part of a separate FCI. While the DR site nodes are built on the same WSFC as the Primary site they are excluded from the FCI at the primary site. Nodes in the disaster recovery data centre are not given a vote and so they cannot affect quorum.
In synchronous-commit mode the secondary replica can be used for backing up or read-only functions reducing load on the primary replica.
Once again both the Patriot database and the PatriotArchive database need to be placed in the same availability group.
At the primary site automatic failover will take place should a fault occur. Once again in line with best industry practice, in the event of catastrophic failure at the primary site, manual failover is required to the remote DR site. As already outlined above providing the correct processes have been put in place as summarized below in the Disaster Recovery section, changeover to the DR site will involve little more than starting the Patriot Promote DR Utility which will automatically activate all failover procedures required.
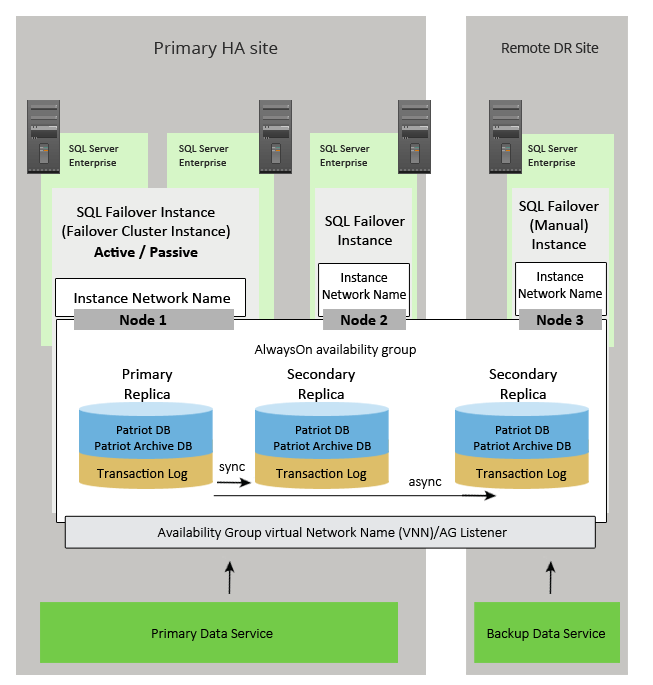
Both of the above solutions include an optional offsite backup using asynchronous replication. As the DR node is still within the availability group, from a Patriot Data service point of view, it all appears as one server. The diagrams above show that the primary Data Service can connect to the SQL DR Node (if active), and the Backup Data Service can connect to one of the SQL Nodes running at the Primary Site. While both these cases are possible they won't be used in practice. The primary Data Service will only ever connect to the SQL Nodes at the primary site. If a failover to the DR site occurs, the Backup Data Service will be used, and it will only connect to the SQL DR Node. See below for Disater Recovery for more details. Also the configuration of the backup SQL Server in the Data Service (at the primary site) settings are not required.
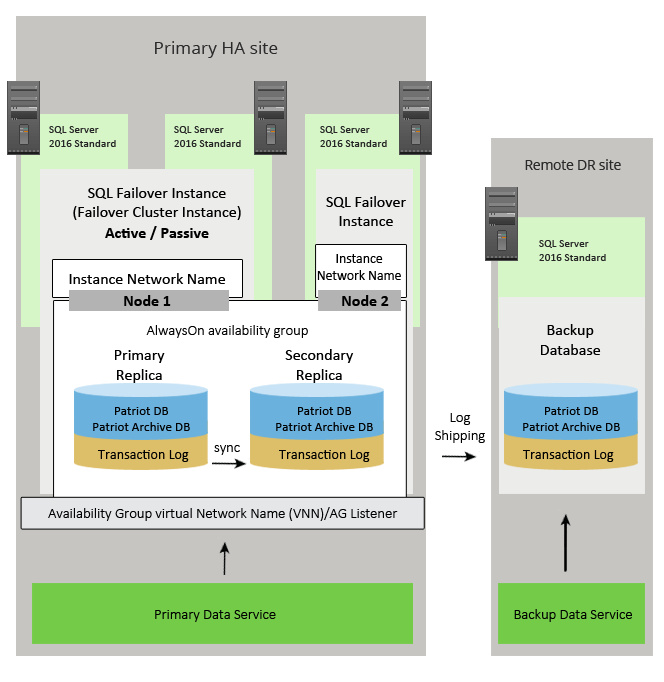
This solution provides the same level of High Availability at the primary location, but uses log shipping to create an offsite (DR) backup. This solution only requires SQL 2016 Standard Edition. Some data loss is likely to occur when failing over to the DR site as log shipping is only carried out at predefined intervals.
Once the SQL clustered server is available, it can be thought of from a Patriot perspective as a normal SQL Server. The SQL cluster will have a single IP address for access.
Install the Patriot database using the Patriot setup wizard following the instructions for installing SQL on a standalone server (ie where the Patriot services are installed on a separate machine).
Then install the Patriot services on the Primary Patriot server (or for clustered Patriot services see below), and optionally on the backup Patriot server as normal. When configuring the Patriot Data Service, and setting the SQL connection settings, enter in the SQL Virtual Address.
Patriot software supports SQL Multi-Subnet clusters. If you are using a Multi-Subnet SQL cluster, Patriot should be configured to enable Multisubnet failover. This setting improves failover detection and recovery so it should always be enabled when using this server setup (Microsoft recommend using this setting for all cluster types even if using a single subnet). To enable this mode, edit the PatriotService.exe.config file in the Patriot Data Service installation folder. Look for the <PatriotService.Settings1> section, and locate the following setting:
<setting name="SQLMultiSubnet" serializeAs="String">
<value>False</value>
</setting>
Change the value to True to enable the multisubnet support. If this setting is missing from your configuration file, add it below the other settings, or contact Patriot support for assistance.
The changes will take effect the next time that the Data Service is restarted.
Note: Multi-Subnet clustering is only supported in the Enterprise edition of Patriot or if you have the Enterprise Database module registered to your license.
The setup of the Patriot Services on a cluster requires Patriot Enterprise Edition or Enterprise Database Module.
Both the Patriot Data service and Patriot Task service can be installed on a Microsoft cluster to provide a high availability solution.
The services are designed to be independent, and will failover (within the cluster) seamlessly with no disruption to other components in the system.
The Patriot Data Service and Task service can be installed on the same cluster as SQL but generally will be installed on a separate cluster. Generally the Data Service and Task Service would be installed together on the same cluster.
The exact configuration and setup of the cluster for the Patriot Services is outside the normal bounds of Patriot support and should be performed by suitably trained IT professionals. Some relevant details will be given below. One requirement is that the services have shared storage. The Patriot Services make use of shared storage for some files not stored in the SQL database, like floorplans, temporary reports etc. The services must be configured to use shared storage (explained below) so there is no loss of data with service failover. It is important that the shared storage is setup using redundant hardware so this doesn't become a single point of failure. The Data service and the Task service can use the same shared volume, but you should create sub folders within this for each service (i.e. create a PatriotTaskService, and PatriotDataService folder within the shared volume.).
The diagram below illustrates the basic structure of the Patriot Service cluster.
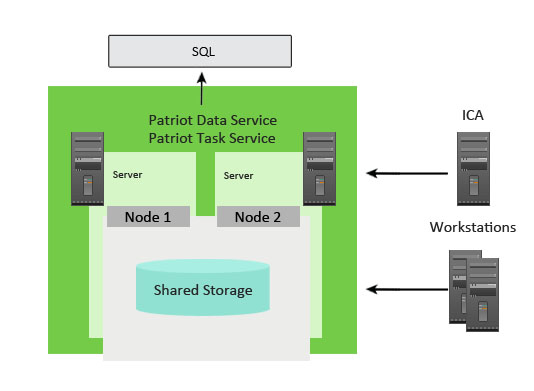
Begin by installing both the Patriot Data and Task services on all nodes. Then edit the service settings and configure into Manual start mode through services.msc as the cluster will handle their starting and stopping.
Once the Services are installed, run the High Availability Wizard to add the Service using the Generic Service option. In the Client Access Point section, give the service a unique Name and Static IpAddress. The name will be used to reference the service by anything accessing it from outside the cluster. In the Select Storage page, assign a volume to the cluster that the service it will use. No changes are required on the Replicate Registry Settings page.
When the roles for the services are setup using the High Availability Wizard, they will automatically enable the option 'Use Network Name As Hostname'. This option must remain checked for the services to function correctly.
Ensure the firewall on all nodes has been properly configured, to allow the services to perform their actions across the network.
External IP Clients
Any alarm receivers etc. which connect to the task service as IP clients will need to be configured to connect to the Task Service access point name or IP as entered during Task Service setup. If these IP Clients are remote, this may only require a reconfiguration of the NAT rules in the firewall.
Task Service
The Task Service will need to be configured to connect to the Data Service access point as entered during the Data Service setup. This will need to be performed on all individual nodes within the cluster. Use the Patriot configurator or edit the config settings file directly in the Task Service install folder.
Ensure the task service has been configured so the local resources are stored in shared storage. To configure this, edit the CSMService.exe.config file in the Patriot Task Service installation folder. Look for the <CSMService.Settings1> section, and update the following setting (add it if its missing):
<setting name="LocalStorageDirectory" serializeAs="String">
<value>C:\ClusterStorage\Volume1\PatriotTaskService</value>
</setting>
In the above example the shared volume is located in C:\ClusterStorage\Volume1\, change this to the location of your shared volume. This will need to be performed on all individual nodes within the cluster.
Check that all tasks setup to run on the clustered Task Service are all configured to run using the Task Service access point name. Note that they will default to the node name when creating new tasks, and will need to be manually changed.
Data Service
The Data Service will need to be configured to connect to the SQL Virtual Cluster Address (assuming SQL is also installed on a cluster). This will need to be performed on all individual nodes within the cluster. Use the Patriot configurator or edit the config settings file directly in the Data Service install folder.
Ensure the data service has been configured so the local resources are stored in shared storage. To configure this, edit the PatriotService.exe.config file in the Patriot Data Service installation folder. Look for the <PatriotService.Settings1> section, and update the following setting (add it if its missing):
<setting name="LocalStorageDirectory" serializeAs="String">
<value>C:\ClusterStorage\Volume1\PatriotDataService</value>
</setting>
In the above example the shared volume is located in C:\ClusterStorage\Volume1\, change this to the location of your shared volume. This will need to be performed on all individual nodes within the cluster.
Client Configuration
Each Patriot Client will need to be configured to connect to the Data Service access point as entered during the Data Service setup. There is no other special setup or configuration required on the client.
Patriot has a Service Orientated Architecture (SOA) and clients communicate with the Patriot Data Service in a restful disconnected fashion. Should the Data Service fail over to a different node with its clustered server, the client may experience a short disruption, but will automatically reconnect once the failover has completed.
A SQL cluster has built in redundancy. If one of the nodes should fail, another node will take over automatically if required. This will have the effect of making SQL unavailable momentarily. The data service is designed to handle this situation. You may get notified that a signal failed to log, but it will get logged soon after on a retry once SQL comes back online. So no signal or data lose will occur in this situation. No intervention is required.
A Patriot Service cluster also has built in redundancy. Failover to alternate nodes will happen automatically. Clients connecting to the Data Service may experience a short disruption, but will reconnect automatically as soon as the failover has completed. No intervention is required.
For failover procedure to the offsite backup (DR), see Disaster Recovery below.
The recommended approach to patching the Patriot software in a clustered environment is as follows,
Apply the patch to all the non-active nodes. Note the auto patcher will default to not restarting the services and will give you a warning regarding this. Ignore the warning, the services should not be started on non-active nodes.
Copy the patch file into the Shared Storage / PatriotDataService folder (to allow easy client patching).
Inform clients to shut down, using operator messaging.
Manually failover the active node onto one of the newly patched nodes.
Inform all clients to restart. At this point the clients will be notified that a patch is available to be applied and request their confirmation before the patch is automatically applied.
Finally apply the patch to the node that was previously active.
If you have complete ownership & control of a second control room you should merge the databases to a single site and have the primary control room DB replicated the secondary control room which would act as the Data Recovery Centre. Both control rooms could be manned and performing normal monitoring duties but all workstations would be accessing the same DB back at the primary control room.
This scenario provides greater operator load sharing flexibility. For instance if you have two control rooms inin separate states (a Primary and a Secondary) - under normal conditions you may want both stations to deal with alarms in their respective states to provide some degree of localization. However when one centre is overloaded (e.g. during a storm) you may want to open its alarms up to the other station so that operators in the quiet control room can assist to get on top of the situation.
This is very easily achieved in Patriot by operator client group assignments. For instance the primary control room may be monitoring VIC, NSW, QLD and the secondary SA, NT, WA TAS. A storm may occur in VIC so the duty supervisor (who could be located at either centre) with the click of a checkbox on secondary station operators would allow the operators to begin handling alarms from all states. When the storm settles down the duty supervisor simply enables the operator client group filtering again and each centre is returned to monitoring its localized states.
Having multiple control rooms in also beneficial in the case of a disaster recovery total fail-over. Allowing operators in all online control rooms to handle cases from the ones affected by the disaster affected. Preventing a disaster which only affects your control room from affecting the monitoring of the entire area such as a fire.
See: Operator Preferences
Note that Patriot’s Service Orientated Architecture (SOA) makes all this sort of stuff possible & clean. Patriot’s Task service which is also a thin client connecting to the main data service (the patriot engine room). Tasks can be run in many configurations. A single instance of the patriot task service can run all or many tasks on a single server or multiple instances of the task service can be run within the local network or in remote locations.
To protect against a disaster that affects the entire Primary Monitoring Centre, it's recommended that an offsite disaster recovery (DR) location be established. The DR site should be able to be brought online simply and quickly and provide all essential monitoring services. There is also a requirement for little or no data loss to occur.
While it is technically possible to setup a fully redundant system with automatic failover to the DR Site, the general consensus is that this is not recommended. The process of failing over to the DR site should involve some manual intervention. Using the guidelines below this process can be made very simple and fast.
There are three main components to consider when planning for your DR location; Data Replication, Remote Patriot Infrastructure, Signalling Redirection.
This section covers how to ensure a copy (exact copy or at least a very recent copy) of the database is available for use at the DR site when needed. There are three options available,
SQL Cluster (Preferred Solution)
Where SQL Clustering is used, the above HA examples both support offsite data transfer using asynchronous replication. So a live copy of the data will be available at the offsite location when required, with little or no data loss.
Along with the actual data being transported to the DR site, the SQL Services must also be started at the DR site. When the DR site is required, the SQL node at the DR site will need to be manually failed over. This will start the SQL services, and bring the database online. The manual failover can be included in the Promote DR Utility (see below).
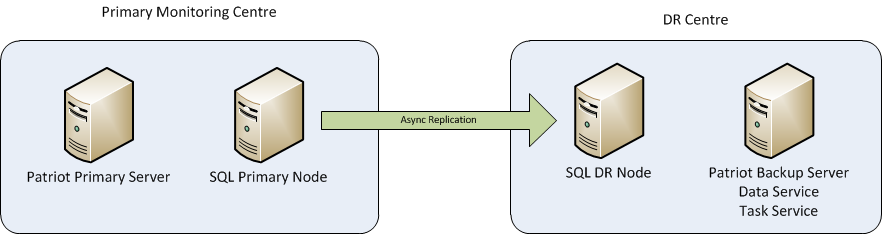
DR Data Replication
While it is possible to configure the cluster so the SQL node at the DR site will failover automatically, there is additional hardware required (witness) and also the risk that the DR node fails over unexpectedly. For these reasons this solution is not normally implemented.
SQL Log Shipping
If SQL clustering is not used, the data can be transferred to the offsite location using SQL log shipping. Log shipping transfers database changes in regular intervals, so there will be some data lost (between one and two intervals worth of data).
With Log Shipping the SQL database at the DR site is normally in a state where is can’t be accessed and needs to be brought online when failing over to the DR site. This step can be included in the Promote DR Utility (see below).
SQL Database Mirroring
Database mirroring could also be used to create a replicated database at the DR site, with the following restrictions,
When configuring SQL mirroring it must be setup in asynchronous mode to work reliably to the remote DR site. With Mirroring, the SQL database at the DR site is normally in a state where is can’t be accessed and needs to be brought online when failing over to the DR site. This step can be included in the Promote DR Utility (see below).
When failover to the DR location is required, a server running the Patriot Data and Task service will be required at the offsite location.
Separate Remote Backup Server
A separate server (Patriot DR Server) must be located at the offsite location with the Patriot Data Service and Patriot Task Service installed. The redundant alarm receivers also located at the offsite location would be configured to communicate with this DR server. These alarm receivers would be made inactive to ensure no signals are inadvertently received through them. Most alarm panels allow for a secondary receiver number however this should never be directed to the DR site because if the primary network or PTSN lines were temporarily down these would want to still be received at the Primary site.
The Patriot services on the Patriot DR Server would be set to manual start-up mode, and left in a non-running state. When failing over to the backup location, the Patriot services needs to be started (see Promote DR Utility below), along with the backup alarm receivers.
Where SQL Clustering is used with asynchronous replication, the Backup Data Service should be configured to connect to the SQL availability group virtual network name (this same name spans acroos both sites). In all other cases, it should be configured to connect to the SQL Server at the DR site.
Backup Receiver Tasks
An appropriate receiver task will also need to be preconfigured to run on the backup task service. This can be setup from any workstation and the details will be replicated to the offsite location using whichever means has been setup. Ensure the correct computer name (name of server at offsite location) is entered, and the Backup setting is also checked in each task. Once these backup tasks are in place, it becomes a very simple process of just starting the Patriot services when failover is required.
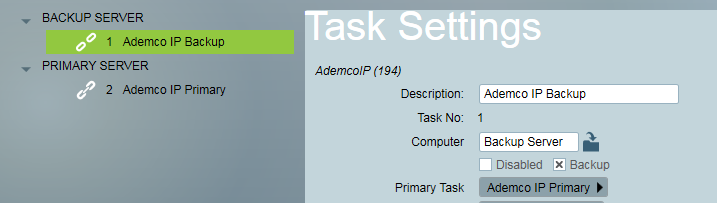
Backup Tasks
Remote Workstations
An adequate number of workstations will also need to be made available at the DR site. Or alternatively remote workstations could be configured on the DR Servers, so operators can connect remotely to the DR site. All these workstations should be pre-configured to connect to the Patriot Data Service running at the DR site.
Signalling redirection involves redirecting the alarm signals from reporting to the primary location to reporting to the DR location. It is assumed that for each alarm receiver used at the primary location, a duplicate receiver will be located at the DR location.
There are various solutions to signalling redirection, some options include,
IP Reporting with Three Contact Points (Preferred Solution)
If the alarm system is reporting using a modern IP based reporting system that is capable of at least three contact points, two points can be located at the primary monitoring station, and an additional point can be setup at the DR location. This gives dual path reporting to the primary location, and then an alternate third path when failing over to the DR location. The level of automation and failover process does depend on the service provider in question. For instance with Permacon the third connection would need to be manually started by calling the 24 hour support service or manually failing over using a service provider application. Inner Range Multipath on the other hand will begin communicating with the DR site as soon as the Patriot Task Service is kicked into life at the DR and begins acknowledging heartbeats.
A backup task should be pre-configured to run on the Patriot DR Server for each different IP receiver located at the DR Site, and also for each type of alarm panel reporting directly to Patriot. See Backup Receiver Tasks above.
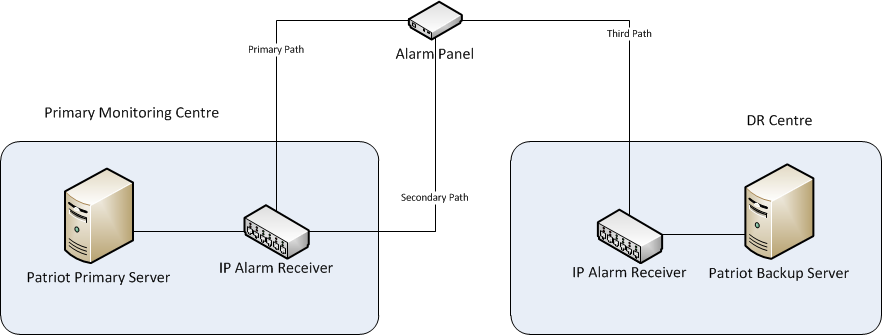
IP Reporting - Three Contact Points
IP Reporting with only Two Contact Points
Where the IP device only has two points of contact (primary and secondary) you can set the secondary to point to the DR location. As the secondary path is likely to be used in cases where the Primary Monitoring Site has gone offline, Patriot can install a Task Service at the DR location. This will forward the signals onto the Primary location when connected, and fall-back to the DR location when DR fail-over has been initiated. Using this system we can effectively replicate the three contact point setup above.
A backup task should be pre-configured to run on the Patriot DR Server for each different IP receiver located at the DR Site, and also for each type of alarm panel reporting directly to Patriot. See Backup Receiver Tasks above.
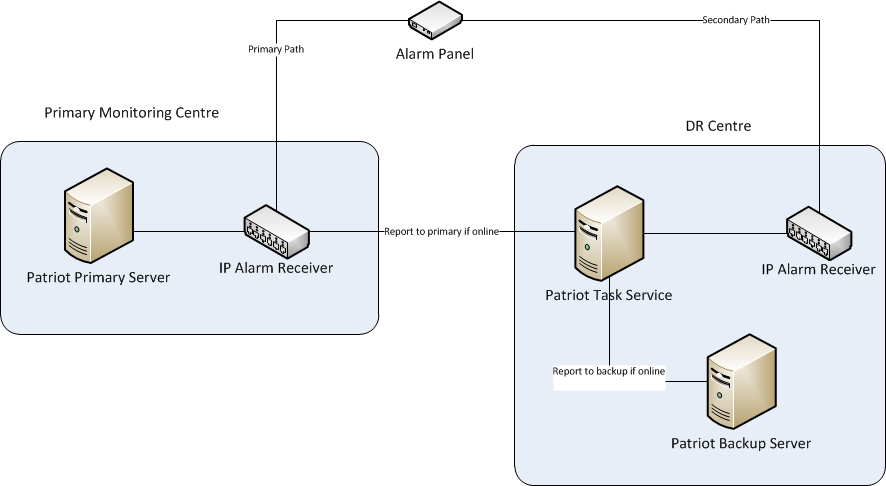
IP Reporting - Two Contact Points
IP Reporting with a Single Contact Point
Where the IP device can only report to one contact point there is no great solution, and these devices should generally be avoided.
A third party DNS Service could be used which can be remotely configured to redirect the signals to the DR site when needed. This does mean you are completely reliant on this third party service being always available.
Alternatively you could install the Patriot Task Service at a third location or the DR site. This can redirect the signals to either the primary site or DR site depending on what is active. But again this means you are reliant on the remote Patriot Task Service always being available.
Another option is to request the service provider to redirect the signalling to the DR site.
IP Panel Reporting Directly to a Patriot Task
The solution used depends on the panels ability to support multiple server addresses. If multiple can be configured, the secondary server point should be configured to connect to the Patriot Task Service run at the DR site, which will allow redirection to the appropriate Data Service.
Remote Call Divert
Where alarm receivers are connected to phone lines, the phone lines can be diverted to the DR location using remote call divert provider (available in some countries) or through your telecommunication provider. The method of call divert should be pre-arranged with your telecommunication provider. The redundant alarm receiver must be configured in exactly the same way (identical handshakes, line card and receiver numbers duplicated) as the receiver at the Primary site.
A backup task should be pre-configured to run on the Patriot DR Server for each redundant receiver located at the DR Site. See Backup Receiver Tasks above.
There are several steps required to bring the DR site online. To make this as easy as possible, these steps can all be scripted, and setup in the Patriot Promote DR Utility located at the DR site. This then makes the process as easy as a single button click. It can be configured to perform the following actions,
Once done the only other actions required are,